Building the VM creation API for the org
20 Jun 2021 #softwaredevelopment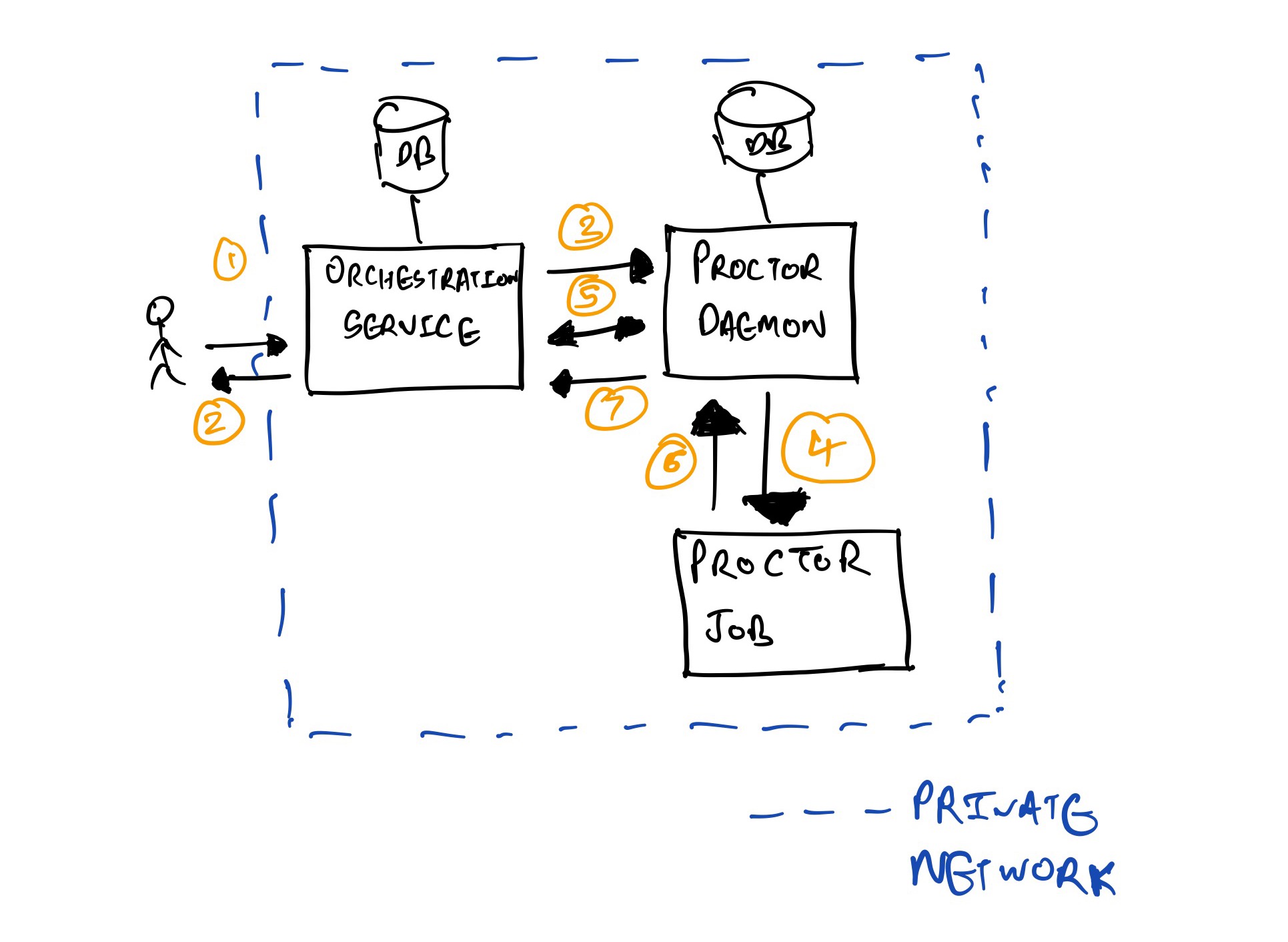
Over the years, there have been a lot of changes in the way, people create their virtual machines in their cloud environment.
At a very primitive level, one would simply go about doing it via the cloud provider console. A couple of clicks and lo and behold.
At a larger scale, people end up using automation to create these Virtual machines in the way they want them to be, given the manual nature of work would just start becoming a bottleneck in scaling quickly when required otherwise.
So how did we go about it?
Existing solution
I have spoken a bit about our current automation using proctor,
I will not delve more into that, but in gist, we had a way present in which developers could simply demand a VM getting created via a cli interface.
As time went by, the automations to create different variations of virtual machines based on language stack kept getting added, helping developers create Virtual machines on demand for their use cases.
This post is about how we ended up making the building block for a lot of automation around Virtual machine creation orchestration inside the org, as part of the platform team.
What is the need for a VM creation API in the first place?
Yes, true. Everything is working fine and dandy. People are able to create VM’s on demand whenever they want and however they would like to, via proctor and everyone is happy so far. What’s the issue then?
We come along with a couple of deprecation plans for the virtual machine infrastructure, where we have to deprecate whole fleets of VM’s for applications which were running on 16.04, which got deprecated in April this year.
It started with adding support for 20.04 to all the automation present in the org, to be able to support creating 20.04 VM’s via proctorˀ. It meant adding support to all the proctor automation scripts which we had, testing them out and so on and so forth.
The part to note here is that the automation’s interface was still the same via the command line tool to create VM’s for end users.
What we ended up doing
We already had a service which we had written to create kubernetes clusters on demand. Rughly, each kubernetes cluster would simply be a resource for this service, where it would store all the cluster related metadata.
Given the programmatic way of creating the kubernetes clusters (although I will share more about the challenges of this approach of creating and managing k8s clusters in another post), we wanted to add another resource on top of our modelling for this service. The service would at the end just call proctor and send it POST calls to create VM’s and have a callback link which this service would poll at the end of the day to check whether the given resources were created at the end of the day or not.
One difference from proctor, which would come here is that, one could ask for multiple VM’s getting created for the application which the service was trying to create VM’s for.
We also ended up changing the way the resources were named, to improve upon our existing way of naming resources (more on this later)
There’s now a central place where we are storing, which applications are running which version of VM’s and how many of them, of what language stack and what OS flavor and other additional metadata.
We also ended up adding a client for it, which people could use to create VM’s of their choice of demand, adding all the necessary helper methods (polling, checking resource status etc.)
User Flow
1) The user sends a POST call to orchestration service to the VM creation route, sending all the necessary information in the POST body to create the VM/VM’s for their application. Information like, which application, the environment, the type of VM to pick, the OS version etc
2) Orchestration service validates the request body and presence of certain fields in the request body, which are required for creation of the VM. eg: environment, language stack etc. It would also send a response back to the client, which would include the information like the VM names etc, which would be something which the user would find useful. Given the async nature of the response, we store the state of the creation of the VMs for each resource. The client can query the resource and the response body would also send the state details of the resource.
3) Orchestration service constructs the information required to send to proctor daemon to call the right proctor job, with the correct request body, sending multiple requests to proctor in case multiple VM’s are requested for creation.
4) Proctor daemon runs the automation to create the VM in a background job to provision and configure the VM.
5) Orchestration service polls proctor daemon for the job which was scheduled to create the VM, with a default backoff present.
6 & 7) proctor job completes, if the poll gets a response within the appropriate time, the status of the job is saved in orchestration service, which decides the final status of the resource in orchestration service DB too.
The user can at this point, make a GET call on the resource URI, to see the updated resource status to check what’s the current state of the state machine.
How has it been used so far
The very first thing, this API got used for was to automatically create our version of managed instances by the productivity team inside engineering platform. It’s a lovely abstraction which they came up with, but simply put, people would ask for a new application to be created from our developer portal, choosing what tech stack to use and which environment. Whether they would want a private reverse proxy or a public one. And they would get their VM’s automatically created for the application along with the loadbalancers, along with mapping the DNS’s to the respective loadbalancers.
The VM’s would get lazily created i.e the first time any deployment would happen on them and then moving forward the records of the infrastructure, which got created would then map to the application for the evironments.
This was as compared to where developers would have to create all the Virtual machines via proctor manually and do the above by themselves. Which led to a lot of time saved while creating a new application for a team.
Another problem statement which got easier due to this VM creation API, was the process of deprecating virtual machines of certain language stacks/OS versions
Recreating VM fleets became easier and programmatic and people could now build their own tooling on how they wanted to create VM’s, which we ended up building for starters for deprecating VM fleets for managed services which we talked about earlier.
Why didn’t we add it in proctor itself?
A couple of reasons. We already had a service which was used to create k8s clusters on demand. We wanted to add another resource to it, which would be used to create virtual machines, making it the central tool to orchestrate resource creation, the resource here could be anything, from a virtual machine to a k8s cluster.
We also felt it would be just cleaner as in interface, where proctor would be fronted by this orchestration service for resource creation and be the entrypoint for developers and the like for having any automation around resource creation needs with helper methods added to the client for their ease of use.
Could we have built everything back in proctor? Defintely. Would it work the same way as it does now? Mostly yes.
But we took to call to move the orchestration bit of every resource going forward to this new service. Be it orchestration of creation of new VM’s, new k8s cluster etc. This service would have the modelling to handle the creation, along with the inventory which we would get out the box (can be solved by other ways, proctor too in this case)
Moving forward
The end result was a lot of time saved in terms of developer time which they would have otherwise spent to create VM’s, cycle VM fleets with minimal developer intervention.
Which is the original and broader goal of automation too I feel, to move out more and more things out of the human hands so that people can move on to do other things. And as always, automation is a moving target for everyone, you build abstractions on top of abstractions sometimes to ease things out for everyone, without compromising on the usual things like quality of what is being delivered, ease of using.
Final thoughts
Creating this along with Vidit and Kartik was such a great experience. Thanks for the learnings.